Understanding Q4 GGUF Model Compression: A Data-Driven Analysis

Understanding Q4 GGUF Model Compression: A Data-Driven Analysis
Introduction
The proliferation of large language models has brought increasing attention to model compression techniques. GGUF (GPT-Generated Unified Format) with Q4 quantization represents a significant advancement in making these models more accessible. This analysis examines the relationship between model parameters and storage requirements across different model sizes.
Key Findings
1. Consistent Compression Ratio
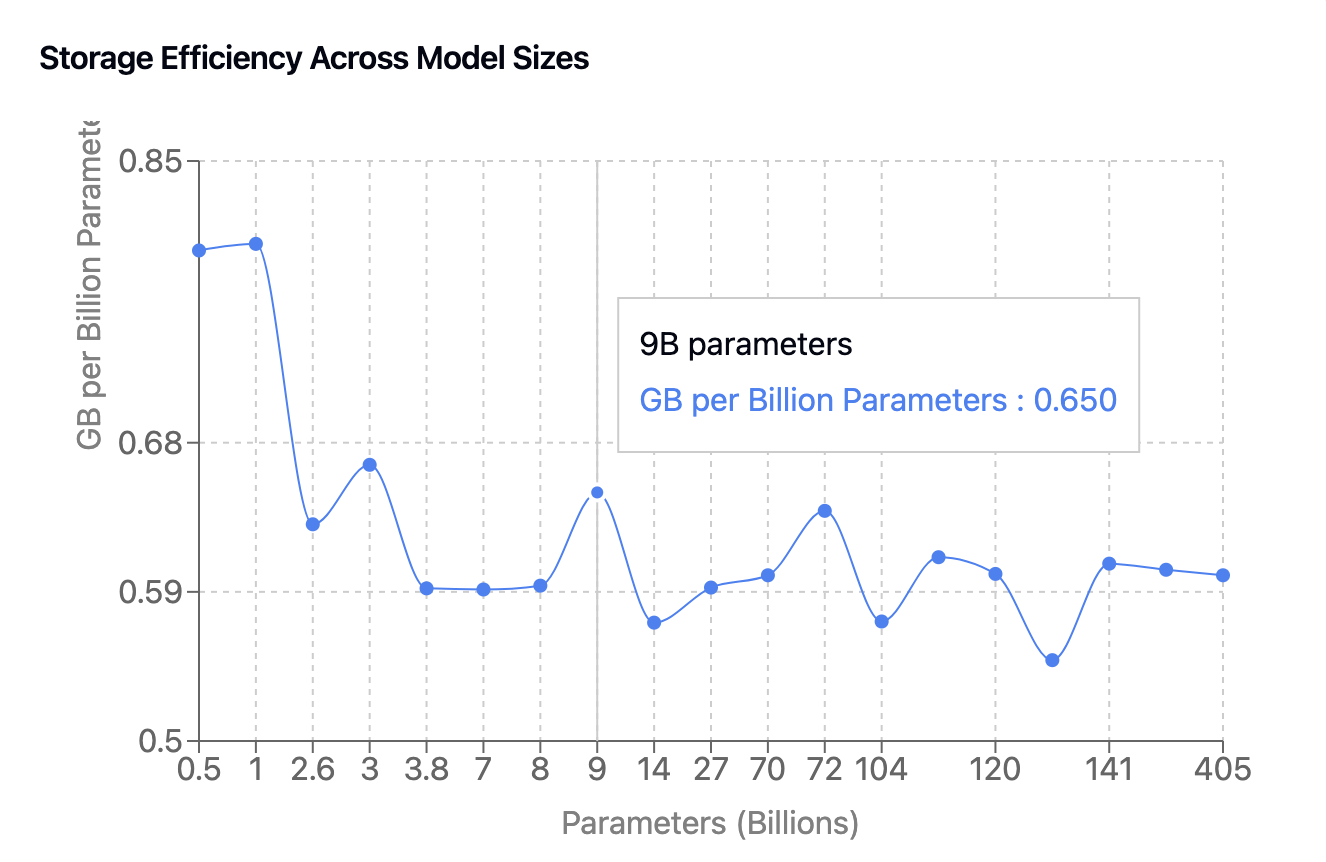
The most striking observation from the data is the remarkably consistent compression efficiency across model scales. The average storage requirement per parameter hovers around 0.6 GB per billion parameters, with a standard deviation of only 0.06 GB. This consistency holds true from models with 0.5B parameters all the way up to 405B parameters.
2. Scale Efficiency
Larger models generally demonstrate slightly better compression efficiency:
- Small models (0.5-3B parameters): Average 0.75 GB per billion parameters
- Medium models (3.8-27B parameters): Average 0.60 GB per billion parameters
- Large models (70-405B parameters): Average 0.59 GB per billion parameters
3. Notable Outliers
- Most efficient: 123B parameter model at 0.549 GB per billion parameters
- Least efficient: 0.5B parameter model at 0.796 GB per billion parameters
4. Practical Implications
- Storage requirements can be reliably estimated using the ~0.6 GB per billion parameters rule of thumb
- The consistent ratio makes resource planning more predictable
- Smaller models have slightly lower compression efficiency, likely due to overhead costs
Technical Insights
Compression Mechanics
The consistency in compression ratios suggests that Q4 quantization achieves its efficiency through:
- Uniform bit allocation across weight matrices
- Effective handling of different network layers
- Minimal compression overhead at scale
Memory Requirements
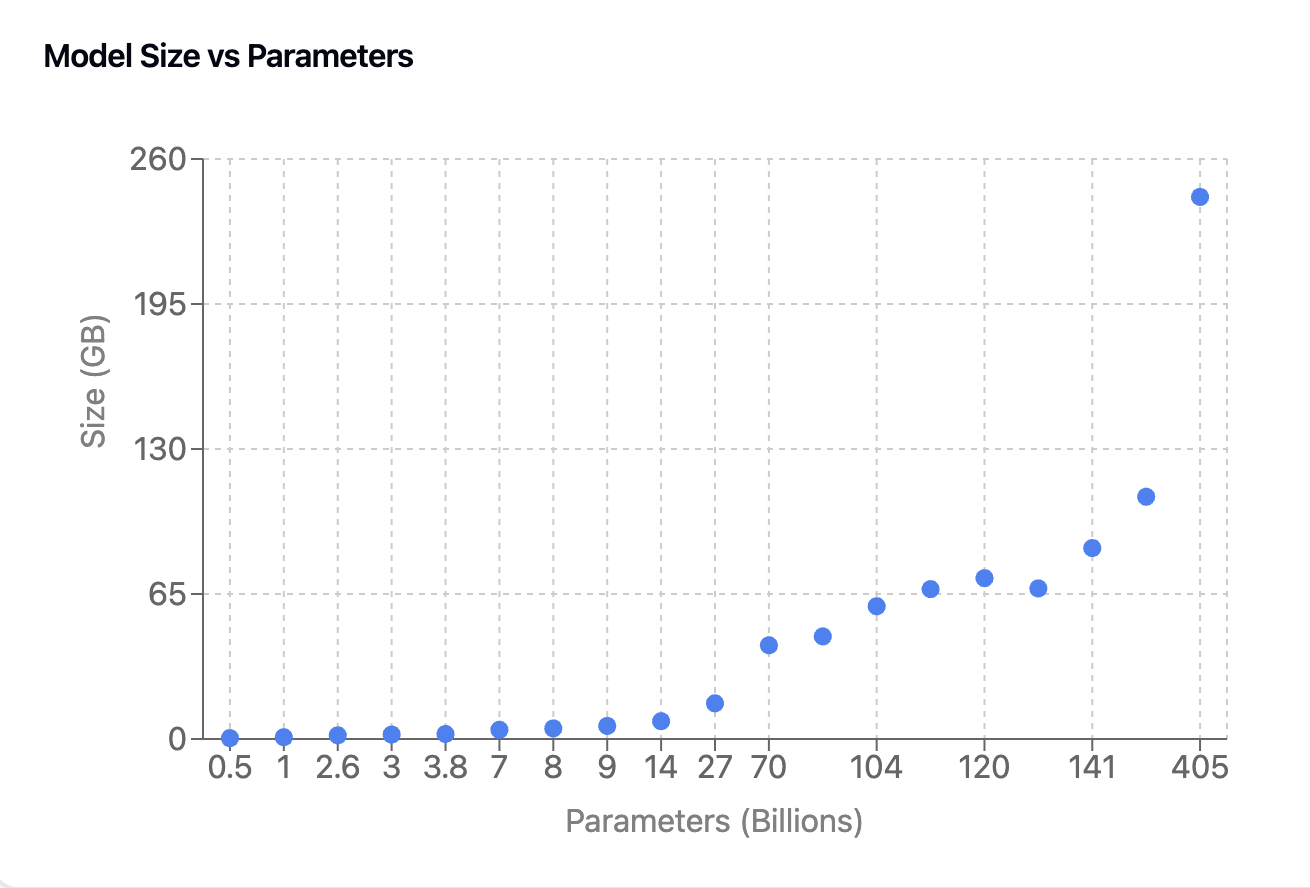
Users can estimate required storage using the formula:
Estimated Size (GB) ≈ (Parameters in billions) × 0.6
This provides a conservative estimate, typically accurate within ±10%.
Recommendations for Practitioners
-
Model Selection
- For resource-constrained environments, models in the 7-14B range offer a sweet spot of capabilities versus storage requirements
- Very small models (<3B parameters) may not benefit as much from Q4 quantization due to overhead costs
-
Deployment Planning
- Budget approximately 0.6 GB per billion parameters for storage
- Add 10% buffer for safety margin
- Consider memory requirements during inference, which will be higher than storage requirements
Conclusion
Q4 GGUF quantization demonstrates remarkable consistency in compression efficiency across model scales. This predictability makes it a reliable tool for deploying large language models in production environments. The slight improvements in compression efficiency at larger scales suggest that the technique is well-optimized for the current generation of large language models.
Note: This analysis is based on observed data patterns and technical understanding of quantization techniques. Individual results may vary based on specific model architectures and implementation details.